10 good Reasons to use the crwlr Library
I'm very proud to announce that version 1.0 of the crawler package is finally released. This article gives you an overview of why you should use this library for your web crawling and scraping jobs.
Reducing Boilerplate Code and improve Readability
Over the years I noticed that I was often writing the same snippets again and again when building crawlers. So, a big reason to build this library was to reduce boilerplate code as much as possible and at the same time try to improve readability. Let's look at an example:
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
$httpClient = new Client();
$url = 'https://www.crwlr.software/packages';
$response = $httpClient->get($url);
$responseBody = $response->getBody()->getContents();
$dom = new Crawler($responseBody, $url);
$packages = $dom->filter('#content .grid > div')->each(function (Crawler $element) {
return [
'title' => $element->filter('h3 a')->text(),
'url' => $element->filter('h3 a')->link()->getUri(),
'description' => $element->filter('p')->text(),
];
});
var_dump($packages);Here we're using guzzle and the symfony DomCrawler component to get all packages (with title, url and description) from the package overview on this site. It's a very, very simple example, so it's not a huge load of code and not very hard to understand. But let's see what it looks like using the crawler package:
use Crwlr\Crawler\HttpCrawler;
use Crwlr\Crawler\Steps\Dom;
use Crwlr\Crawler\Steps\Html;
use Crwlr\Crawler\Steps\Loading\Http;
$crawler = HttpCrawler::make()
->withBotUserAgent('MyCrawler');
->input('https://www.crwlr.software/packages')
->addStep(Http::get())
->addStep(
Html::each('#content .grid > div')->extract([
'title' => 'h3 a',
'url' => Dom::cssSelector('h3 a')->link(),
'description' => 'p',
])
);
foreach ($crawler->run() as $result) {
var_dump($result->toArray());
}We only have to create a crawler instance with some user agent, and after this, the code is really focused on what we actually want to do: load a website (Http::get()) and extract some data from it (Html::each(...)->extract([])). We don't have to create an HTTP client instance, manually get the body from the response and create a symfony DomCrawler instance from it.
Further I think it improves readability a lot, because the classes, providing the steps via static methods, show the intent. Some other steps are: Html::getLinks(), Html::schemaOrg() or Sitemap::getSitemapsFromRobotsTxt().
Low Memory Usage by Design
Crawlers are programs that often have to process large amounts of data, which is why the library uses generators to be as memory efficient as possible.
If you haven't used generators before, here's a very brief explanation: When a function returns an array, all the elements of that array are in memory at once. It's like a pallet of bricks. You can iterate over it to get the single bricks, but the program still has the full pallet in memory at once. To be more memory efficient, you can make the function return one element (brick) at a time, using the yield keyword, which causes, that the function returns a Generator. When calling the function, you have to iterate over the return value in a loop. And inside one iteration of that loop, there exists only that one element (brick) that you're currently processing. The function never creates the full pallet of bricks, just one brick at a time on demand. If you're still confused, you can read more about generators on Amit Merchant's blog.
That being said: the main functions behind all steps are returning generators (you also have to do so when building custom steps). This makes it possible, that a single output can trickle down the chain of steps until the end before the next output is even created.
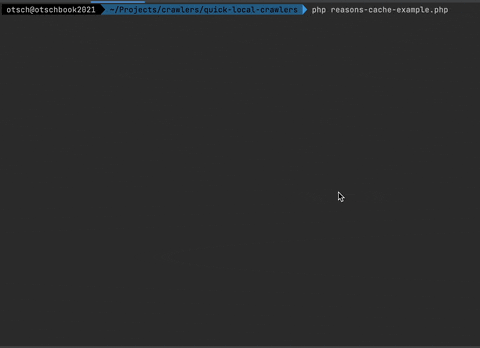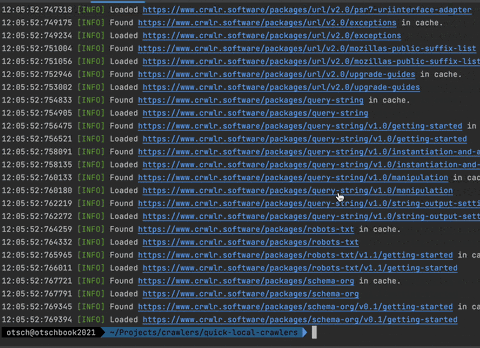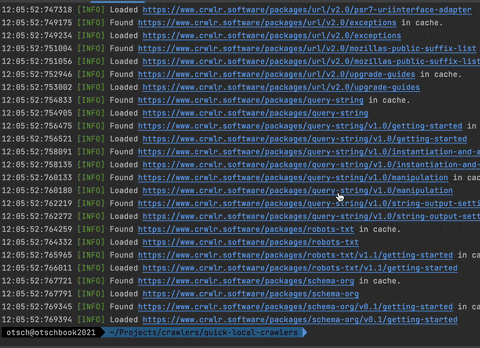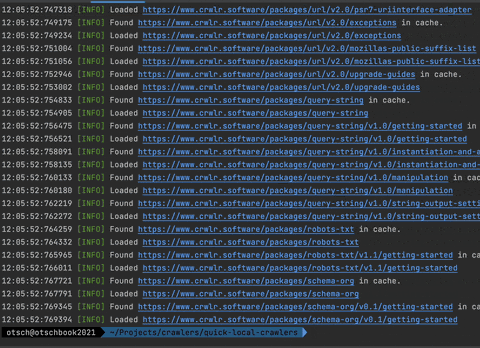
Response Cache
One of my favorite features is the response cache! You can add an instance of the PSR-16 CacheInterface to your crawler's loader, and it will cache all loaded responses. The package ships with a simple implementation called FileCache that saves the responses in files in a directory on your filesystem.
Why is this so cool you ask? Well, you can e.g. use it during development. After you've run your crawler the first time, and it loaded and cached all the pages, you can re-run it again and again really fast without having to wait for actual HTTP responses. As a side effect you're also not unnecessarily producing load on someone else's servers.
Another use case is, when you're having a very long-running crawler that loads a lot of pages. It could be very frustrating when it fails for some reason, after it already ran for half an hour. If you're using a cache, you can just restart it, and it will be at the same point where it failed really fast.
Helpful Log Messages out of the Box
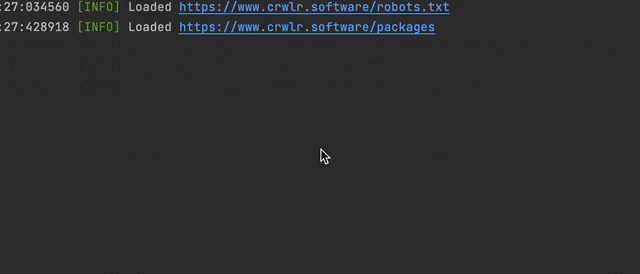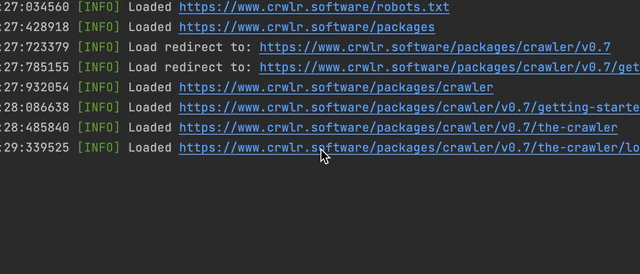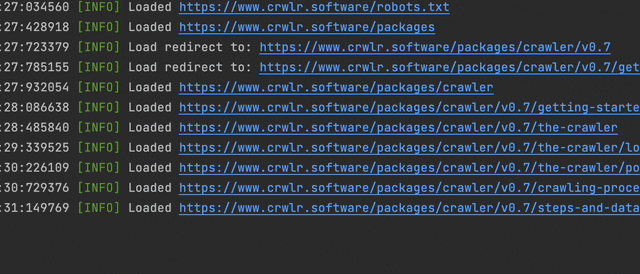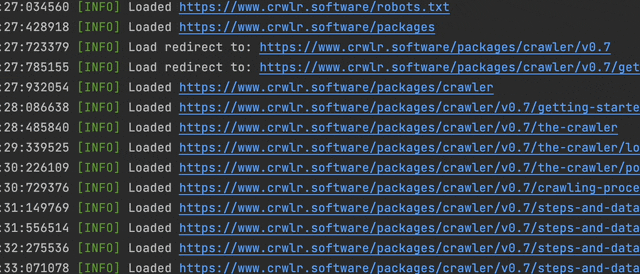
Crawlers built with this library use an implementation of the PSR-3 LoggerInterface to log messages. If you don't provide your own, it uses the CliLogger shipped with the package that just echoes messages, formatted for command line output. The crawler passes the logger on to all the steps added to the crawler, so they can log what they are doing, or if something went wrong. Of course, you can also use it from custom steps that you're building. If you want to send your log messages somewhere else (e.g. write to a file or to some database), implementing your own PSR-3 LoggerInterface is very easy too.
Built-in Crawler/Bot Behavior and Politeness
This may partially not be interesting for everyone, but I think it's good to know, that the library has built-in mechanisms that try to avoid that your crawler gets negative attention from website owners.
Respecting Rules in robots.txt
If you decide to use this, the crawler will load the robots.txt file before the first request to a URL on a host, and respect the rules defined in there. You decide, by choosing either an instance of the BotUserAgent or the UserAgent class, as the user agent for your crawler. If you use a BotUserAgent it sticks to the rules. More about the feature, here.
You may ask: Why should I stick to robots.txt rules, I'm not some official search engine crawler?
Well, there is at least one reason why you might at least want to be careful: Honeypot traps.
More and more website owners use so-called honeypots to identify bots and block them. How does this work? A website owner places a hidden link to a URL that is only used for the honeypot purpose. The link is not visible on the website, so no actual user will ever go there, only bots. So if there's a request to that route, they know, the request is coming from a bot. In most cases, that URL is also listed in a disallow rule in the robots.txt file. So, polite crawlers and bots, which are obeying the rules, will never load that URL and therefor not be blocked.
Besides respecting the rules from the robots.txt file, the library also comes with functionality, to get sitemap links from there.
Throttling
Without using the library you will maybe just send one request after another, or even parallelize them. Website owners often monitor their traffic or have rate limits and may block you (by user-agent and/or IP) when crawling too fast. This is from wikipedia's robots.txt file:
# Please note: There are a lot of pages on this site, and there are
# some misbehaved spiders out there that go _way_ too fast. If you're
# irresponsible, your access to the site may be blocked.By default, the HttpLoader shipped with the package waits a bit between two requests to the same host. The time that it waits depends on the time, that the previous request took to be responded. This means, that if the website starts responding slower, the crawler will also crawl slower. Even if the high load on the website is not your crawler's fault, it's a nice thing to do, isn't it?
But of course you can also customize this. You can even configure to not wait at all between requests, if you know that it's OK.
Wait and Retry when receiving certain Error Responses
This is particularly about two kinds of error responses:
- 429 - Too Many Requests
- 503 - Service Unavailable
When the loader receives one of those, it waits and retries. The time to wait, max time to wait and amount of retries is configurable. If the response contains a Retry-After HTTP header, it waits as long as defined there, except if it exceeds the defined max time to wait. Read more about the feature here.
Goes beyond HTTP and HTML only
A lot of crawling/scraping libraries are built to only parse HTML documents and load them via HTTP. But sometimes you may need to get something out of other types of documents (JSON, XML, CSV,...) or even load documents via something else, like FTP. OK, the library currently ships with the HttpLoader only, but others will come, and you could already implement a custom loader if you want to. What's already included are steps to get data from XML, JSON and CSV documents.
Needing other loaders may be more of an edge case, but there are a lot of use cases where you need to get something from non HTML documents. For example, you want to crawl some articles (or products, or whatever) listed in an XML feed, or received from a REST API returning JSON.
Simple Paginator
A very common problem when crawling, are paginated listings. The package comes with a very simple solution for simple pagination on websites:
use Crwlr\Crawler\Steps\Loading\Http;
$crawler
->input('https://www.example.com/some/listing')
->addStep(
Http::get()->paginate('.next-page')
);When called with a CSS selector, it finds all links either matching that selector or within elements matching that selector. So you can either provide a selector matching only the next page link, or also just the element that wraps all the pagination links. It won't load the same URL twice.
For more complex scenarios, like using POST parameters to paginate, you can implement a custom paginator and maybe there will even be more pre-built paginators in future versions.
Simple and Powerful Helpers to Filter and Refine Scraped Data
These are features, implemented in the abstract Step parent class, so they can be used with any step.
Filter Outputs
Let's say you have a JSON document containing all albums by Queen and you want to get only albums that were released after 1979 and have been number one in the austrian charts. This can be achieved like this:
$crawler->addStep(
Json::each('queenAlbums', ['title', 'year', 'chartPosition' => 'charts.at'])
->where('year', Filter::greaterThan(1979))
->where('chartPosition', Filter::equal(1))
);Read more about this feature here.
Refine Outputs
Often data extracted from a website is not very clean, and you have to manually process it further. There's a convenient way to do this.
use Crwlr\Crawler\Steps\Html;
use Crwlr\Crawler\Steps\Loading\Http;
use Crwlr\Crawler\Steps\Refiners\StringRefiner;
$crawler
->input('https://www.some-example-weather.site/vienna/today')
->addStep(Http::get())
->addStep(
Html::each('#forecast .weatherForHour')
->extract([
'hour' => '.time',
'temperature' => '.temp',
])
->refineOutput('temperature', StringRefiner::replace('°', ''))
);Read more about this feature here.
Clean Solution to Store Scraped Data
Instead of manually iterating over the crawling results and store them, you can add a store class to your crawler, like this:
use Crwlr\Crawler\Result;
use Crwlr\Crawler\Stores\Store;
class MyStore extends Store
{
public function store(Result $result): void
{
// Store the Result however you prefer.
}
}
$myCrawler->setStore(new MyStore());The crawler then internally calls the store() method of this class with every single crawling result.
Read more about this feature here.
Modularity and Extensibility
The modular concept of steps clearly aims at reusability and extensibility. If you develop a step for your own, that could be useful for others, please consider sharing it. If it's something rather general, that can be useful for a lot of people, you could create a pull request at the crawler package. If it's something more special, let's say for example it gets data from sites built with a certain WordPress plugin, it would be great if you'd share it as a separate extension package. It then won't be installed with the crawler package itself, but people can install it additionally.
So, my vision is, that over time an ecosystem evolves from this library, that will make web crawling and scraping even easier than it is now. I hope you'll like it and if there are any questions just contact me any time.