Politeness Features
Crawlers or Bots generally don't really have the best reputation. So it's important for your crawler to behave politely and build trust. The HttpLoader (by default used by the HttpCrawler) has some politeness features built-in.
Respecting robots.txt
You can decide to use this feature automatically by choosing your user agent. If you are going to act as an official crawler (/bot), you should make your user agent an instance of BotUserAgent and the HttpLoader will automatically load the robots.txt file for every host that it's loading URLs on and respect the rules in there. If you're going for a normal UserAgent it won't do so.
Optionally ignore Wildcard Rules
⚠️ Opinion: I've noticed that there are some sites using very defensive robots.txt rules, like disallowing all bots except for some major search engines. I won't go into much detail here as this is a technical documentation, but I think that's not very fair: the big players get a free ride, the actual bad bots won't care about your robots.txt, and the lesser known crawlers and bots, which are playing fair, are disallowed automatically.
So, I don't recommend doing this by default, but if you want, you can tell the HttpLoader that it should only respect disallow rules explicitly for your own user agent and ignore wildcard (*) rules. In that case the loader() method of your crawler should look like this:
use Crwlr\Crawler\HttpCrawler;
use Crwlr\Crawler\Loader\Http\HttpLoader;
use Crwlr\Crawler\Loader\LoaderInterface;
use Crwlr\Crawler\UserAgents\UserAgentInterface;
use Psr\Log\LoggerInterface;
class MyCrawler extends HttpCrawler
{
protected function loader(UserAgentInterface $userAgent, LoggerInterface $logger): LoaderInterface|array
{
$loader = new HttpLoader($userAgent, logger: $logger);
$loader->robotsTxt()->ignoreWildcardRules();
return $loader;
}
// define user agent
}⚠️ This ignores all wildcard rules, not only Disallow: / but also rules like Disallow: /honeypot. Site-owners could use this for example to check if you're respecting their robots.txt rules, by adding a hidden link to the honeypot URL that only bots will find and follow.
Throttling
Some websites are running on server infrastructure that can deal with a lot of traffic, while others don't. And even if they can, site-owners won't like to see clients crawling very fast and thereby consuming a lot of resources. For example have a look at wikipedia's robots.txt file. You don't want to end up being listed there as being a misbehaved crawler.
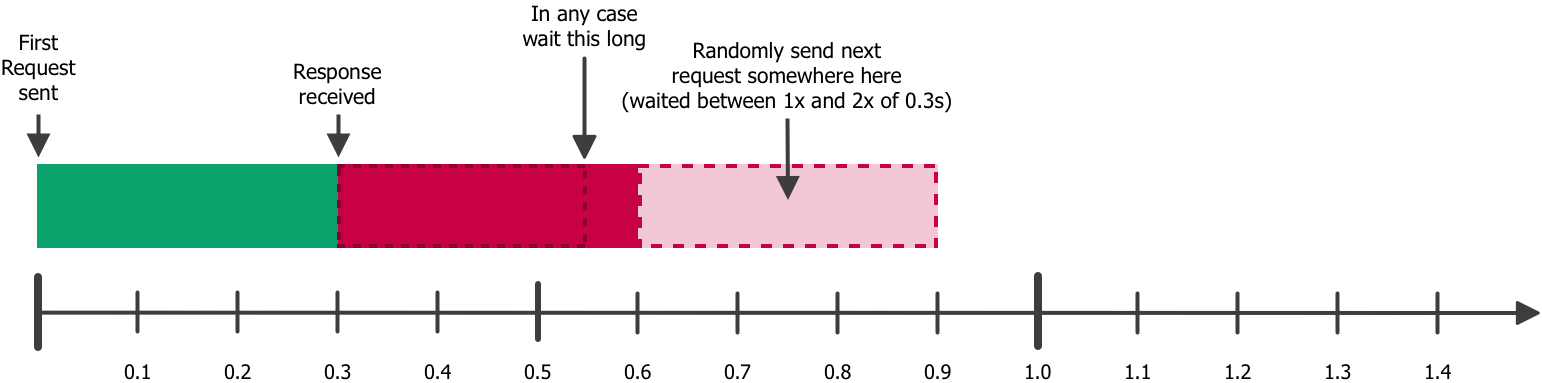
So the HttpLoader has a Throttler which tracks when a request was sent and when the response was received. After the response was received it assures to not send a next request to the same host too early. By default, it waits between 1x and 2x of the time, the last request took to be responded and at least 0.25 seconds. Making the time to wait depend on the previous response time, assures to slow down crawling if a server starts responding slower.
This visualization shows how it looks when the first request takes 0.3 seconds to be delivered:
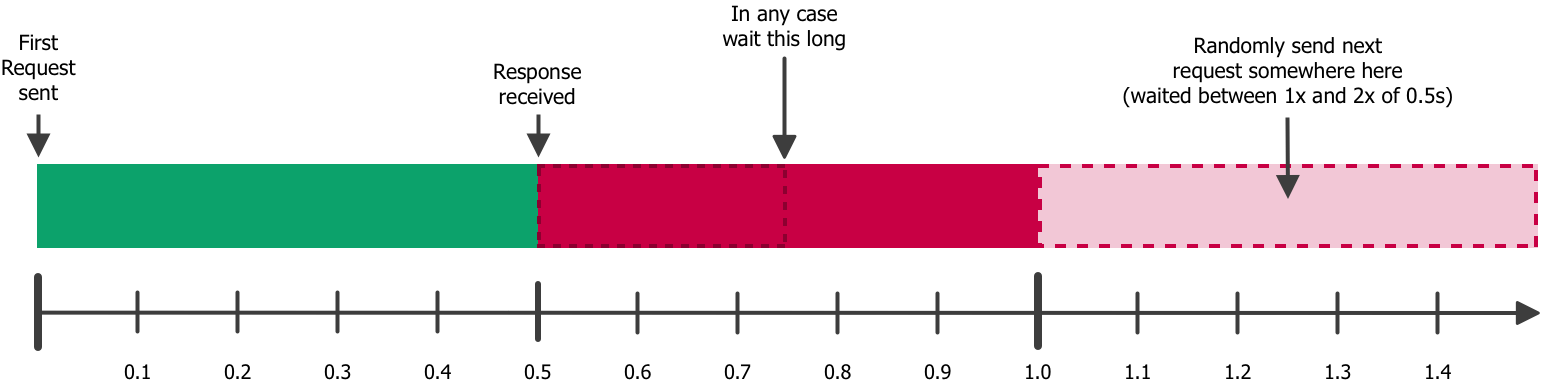
And the same example with 0.5 seconds:
Configure Throttler
You can also configure the Throttler in the loader() method of your crawler class:
use Crwlr\Crawler\HttpCrawler;
use Crwlr\Crawler\Loader\Http\HttpLoader;
use Crwlr\Crawler\Loader\Http\Politeness\TimingUnits\Microseconds;
use Crwlr\Crawler\Loader\Http\Politeness\TimingUnits\MultipleOf;
use Crwlr\Crawler\Loader\LoaderInterface;
use Crwlr\Crawler\UserAgents\UserAgentInterface;
use Psr\Log\LoggerInterface;
class MyCrawler extends HttpCrawler
{
protected function loader(UserAgentInterface $userAgent, LoggerInterface $logger): LoaderInterface|array
{
$loader = new HttpLoader($userAgent, logger: $logger);
$loader->throttle()
->waitBetween(new MultipleOf(2.0), new MultipleOf(4.0))
->waitAtLeast(Microseconds::fromSeconds(1.0))
->waitAtMax(Microseconds::fromSeconds(3.0));
return $loader;
}
// define user agent
}The MultipleOf class, as already explained above means: multiply the time, the previous request took to be responded, with this number. You can also use fixed (Microseconds) values for the waitBetween() method, like:
use Crwlr\Crawler\HttpCrawler;
use Crwlr\Crawler\Loader\Http\HttpLoader;
use Crwlr\Crawler\Loader\Http\Politeness\TimingUnits\Microseconds;
use Crwlr\Crawler\Loader\LoaderInterface;
use Crwlr\Crawler\UserAgents\UserAgentInterface;
use Psr\Log\LoggerInterface;
class MyCrawler extends HttpCrawler
{
protected function loader(UserAgentInterface $userAgent, LoggerInterface $logger): LoaderInterface|array
{
$loader = new HttpLoader($userAgent, logger: $logger);
$loader->throttle()
->waitBetween(
Microseconds::fromSeconds(1.0),
Microseconds::fromSeconds(2.0)
);
return $loader;
}
// define user agent
}So, with these settings it will wait between 1 and 2 seconds before sending the next request. You can also set the from and to arguments of the waitBetween() method to the same value, e.g. 1 second. Then it will just always wait 1 second. The range should just add some randomness.
Wait and Retry when receiving certain error responses
The HttpLoader automatically reacts to 429 - Too Many Requests and 503 - Service Unavailable HTTP responses. If it receives one, it first checks if the response contains a Retry-After HTTP header (https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Retry-After). If there is one, it complies to it and retries after the defined amount of time, provided that it's not longer than the defined maximum wait time (default 60 seconds). If it's longer than that limit, the crawler will stop, because it doesn't make a lot of sense to have it in a waiting state for a very long time. By default, it will retry the request twice. When it still gets a 429 or 503 response after that, the loader stops trying to load that URL. When the response doesn't contain a Retry-After header, by default it waits 10 seconds before the first retry and one minute before the second one.
You can set your own values for this, by providing your own RetryErrorResponseHandler instance to the HttpLoader in your crawler's loader() method.
use Crwlr\Crawler\HttpCrawler;
use Crwlr\Crawler\Loader\Http\HttpLoader;
use Crwlr\Crawler\Loader\Http\Politeness\TooManyRequestsHandler;
use Crwlr\Crawler\Loader\LoaderInterface;
use Crwlr\Crawler\UserAgents\BotUserAgent;
use Crwlr\Crawler\UserAgents\UserAgentInterface;
use Psr\Log\LoggerInterface;
class MyCrawler extends HttpCrawler
{
protected function userAgent(): UserAgentInterface
{
return new BotUserAgent('MyCrawler');
}
protected function loader(UserAgentInterface $userAgent, LoggerInterface $logger): LoaderInterface|array
{
return new HttpLoader(
$userAgent,
logger: $logger,
retryErrorResponseHandler: new RetryErrorResponseHandler(
2, /* The amount of retries the loader should make before stopping */
[5, 30], /* The wait times before each retry in seconds.
* Needs to have as many elements as max retries defined above */
3, /* Max wait time in case response contains a Retry-After HTTP header */
),
);
}
}